Lucene介绍与应用
一、全文检索介绍
1.数据结构
结构化数据:
指具有“固定格式” 或“限定长度”的数据;
例如:数据库中的数据、元数据……
非结构化数据
指不定长度或无固定格式的数据;
例如:文本、图片、视频、图表……
2.数据的搜索
顺序扫描法
从第一个文件扫描到最后一个文件,把每一个文件内容从开头扫到结尾,直到扫完所有的文件。
全文检索法
将非结构化数据中的一部分信息提取出来,重新组织,建立索引,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。
3.全文检索
例如:新华字典。字典的拼音表和部首检字表就相当于字典的索引,我们可以通过查找索引从而找到具体的字解释。如果没有创建索引,就要从字典的首页一页页地去查找。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search) 。
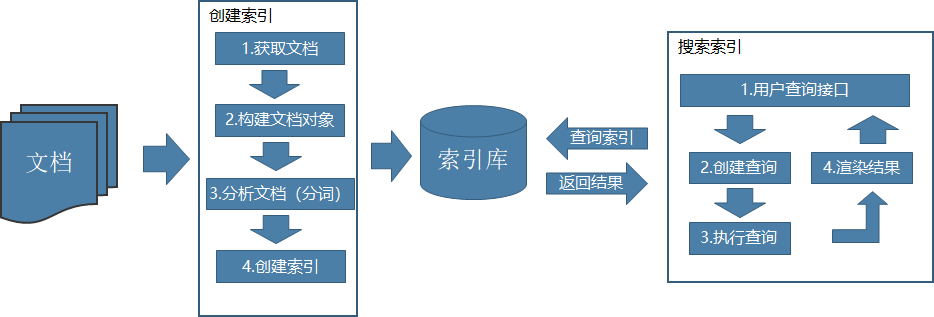
全文检索的核心
创建索引:将从所有的结构化和非结构化数据提取信息,创建索引的过程。
搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
4.倒排索引
倒排索引(英文:InvertedIndex),也称为反向索引,是一种索引方法,实现“单词-文档矩阵”的一种具体存储形式,常被用于存储在全文搜索下某个单词与文档的存储位置的映射,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。
倒排索引的结构主要由两个部分组成:“单词词典”和“倒排表”。
索引方法例子
3个文档内容为:
1.php是过去最流行的语言。
2.java是现在最流行的语言。
3.Python是未来流行的语言。
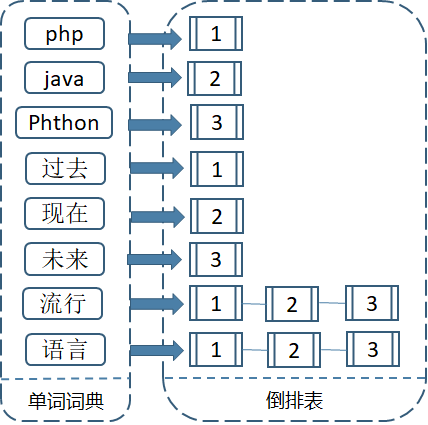
倒排索引的创建
1.使用分词系统将文档切分成单词序列,每个文档就成了由由单词序列构成的数据流;
2.给不同的单词赋予唯一的单词id,记录下对应的单词;
3.同时记录单词出现的文档,形成倒排列表。每个单词都指向了文档(Document)链表。

倒排索引的查询
假如说用户需要查询: “现在流行”
1.将用户输入进行分词,分为”现在”和”流行”;
2.取出包含字符串“现在”的文档链表;
3.取出包含字符串“流行”的文档链表;
4.通过合并链表,找出包含有”现在”或者”流行”的链表。
倒排索引原理
当然倒排索引的结构也不是上面说的那么简单,索引系统还可以记录除此之外的更多信息。词对应的倒排列表不仅记录了文档编号还记录了单词频率信息。词频信息在搜索结果时,是重要的排序依据。这里先了解下,后面的评分计算就要用到这个。
索引和搜索流程图
二、Lucene入门
• Lucene是一套用于全文检索和搜寻的开源程序库,由Apache软件基金会支持和提供;
• 基于java的全文检索工具包, Lucene并不是现成的搜索引擎产品,但可以用来制作搜索引擎产品;
• 官网:http://lucene.apache.org/ 。
1.Lucene的总体结构
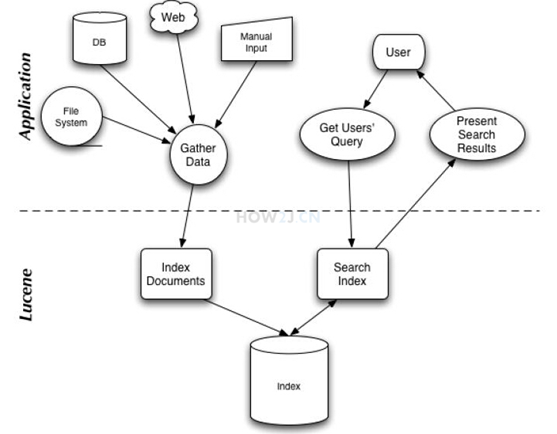
从lucene的总体架构图可以看出:
1.Lucene库提供了创建索引和搜索索引的API。
2.应用程序需要做的就是收集文档数据,创建索引;通过用户输入查询索引的得到返回结果。
2.Lucene的几个基本概念
Index(索引):类似数据库的表的概念,但它完全没有约束,可以修改和添加里面的文档,文档里的内容可以任意定义。
Document(文档):类似数据库内的行的概念,一个Index内会包含多个Document。
Field(字段):一个Document会由一个或多个Field组成,分词就是对Field 分词。
Term(词语)和Term Dictionary(词典):Lucene中索引和搜索的最小单位,一个Field会由一个或多个Term组成,Term是由Field经过Analyzer(分词)产生。Term Dictionary即Term词典,是根据条件查找Term的基本索引。
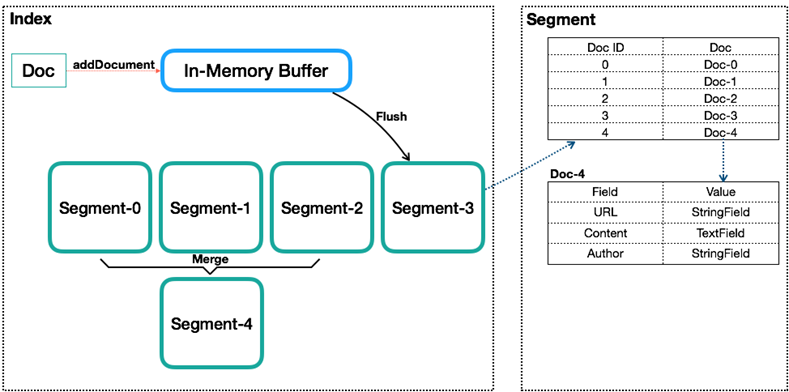
3.Lucene创建索引过程
Lucene创建索引过程如下:
1.创建一个IndexWriter用来写索引文件,它有几个参数,INDEX_DIR就是索引文件所存放的位置,Analyzer便是用来 对文档进行词法分析和语言处理的。
2.创建一个Document代表我们要索引的文档。将不同的Field加入到文档中。不同类型的信息用不同的Field来表示
3.IndexWriter调用函数addDocument将索引写到索引文件夹中。
4.Lucene搜索过程
搜索过程如下:
1.IndexReader将磁盘上的索引信息读入到内存,INDEX_DIR就是索引文件存放的位置。
2.创建IndexSearcher准备进行搜索。
3.创建Analyer用来对查询语句进行词法分析和语言处理。
4.创建QueryParser用来对查询语句进行语法分析。
5.QueryParser调用parser进行语法分析,形成查询语法树,放到Query中。
6.IndexSearcher调用search对查询语法树Query进行搜索,得到结果TopScoreDocCollector。
三、Lucene入门案例一
1.案例一代码
引入lucene的jar包
1 | public class LuceneTest { |
2.代码解析
创建索引
1 | private static Directory createIndex(IKAnalyzer analyzer, List<String> products) throws IOException { |
上面代码是将List中的内容保存在文档中,使用analyzer分词器分词,创建索引,索引保存在内存中。 IndexWriter 对象用来写索引的。
查询索引
1 | // 3. 查询器 |
上面代码是查询代码,首先对构建查询条件Query对象,读取索引,创建IndexSearcher 查询对象,传入查询条件,得到查询结果,将结果解析出来,返回。
分词器
创建索引和查询都要用到分词器,在Lucene中分词主要依靠Analyzer类解析实现。Analyzer类是一个抽象类,分词的具体规则是由子类实现的,不同的语言规则,要有不同的分词器, Lucene默认的StandardAnalyzer是不支持中文的分词。
代码中用到了IKAnalyzer分词器,IKAnalyzer是第三方实现的分词器,继承自Lucene的Analyzer类,针对中文文本进行处理的分词器。
打分机制
从案例返回结果来看,有一列匹配度得分,得分越高的排在越前面,排在前面的查询结果也越准确。
打分公式:

Lucene库也实现了上面的打分算法,查询结果也会根据分数进行排序。
高亮显示
1 | SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("<span style='color:red'>", "</span>"); |
将查询结果放到html页面,就会发现查询结果里关键字被标记为红色。在 Lucene库的org.apache.lucene.search.highlight包中提供了关于高亮显示检索关键字的方法,可以对返回的结果中出现了的关键字进行标记。
四、Lucene入门案例二
1.案例介绍
1.将14万条商品详细信息到mysql数据库;
2.使用Lucene库创建索引;
3.使用Luncene查询索引,并做分页操作,得到返回查询到的数据,并记录查询时长;
4.使用JDBC连接mysql数据库,采用like查询,对商品进行分页操作,返回查询到的数据,记录查询时长;
5.比较mysql的模糊查询与Lucene全文检索查询。
2.案例二代码
引入lucene的jar包,和mysql的驱动包,创建数据库product表,插入数据.
1 | /** |
1 | public class TestLucene { |
1 | public class ProductDao { |
1 | /** |
1 | /** |
4.Lucene的分页查询
1 | private static ScoreDoc[] pageSearch(Query query, IndexSearcher searcher, int pageNow, int pageSize) |
先把所有的命中数查询出来,在进行分页,有点是查询快,缺点是内存消耗大。
5.结果比较分析
1.14万条数据,从创建lucene索引耗时:11678毫秒,创建索引还是比较耗时的,但是索引只用创建一次,后面都查询都可以使用;
2.从查询时间来看,使用Lucene查询,基本都在10ms左右,mysql查询耗时在150ms以上,查询速度方面有很大的提升,特别是数据量大的时候更加明显;
3.从查询精准度来说,输入单个的词语可能都能查询到结果,输入组合词语,mysql可以匹配不了,Lucene依然可以查询出来,将匹配度高的结果排在前面,更精准。
6.Lucene索引与mysql数据库对比
| Lucene全文检索 | mysql数据库 | |
|---|---|---|
| 索引 | 将数据源中的数据–建立反向索引,查询快 | 对于like查询来说,传统数据库的索引不起作用,还是要全表扫描,查询慢 |
| 匹配效果 | 词元(term)匹配,通过语言分析接口进行关键字拆分,匹配度高 | 模糊匹配,可能不能匹配相关的词组 |
| 匹配度 | 有匹配度算法,匹配度高的得分高排前面 | 无匹配程度算法,随机排列 |
| 关键字标记 | 提供高亮显示的Api,可以对查询结果的关键字高亮标记 | 没有直接使用的api,需要自己封装 |
五、总结
首先我们了解全文检索方法,全文检索搜索非结构化数据速度快等优点,倒排索引是现在最常用的全文检索方法,索引的核心就是怎么创建索引和查询索引。至于怎么实现创建和查询,Apache软件基金会很贴心的为我们Java程序员提供了Lucene开源库,它为我们提供了创建和查询索引的api,这就是我们学习Lucene的目的。